[CS330] lecture4 review
in Summary on Summary, Cs330
Question
pi와 theata 의 차이점이 pi는 optimize한 결과 즉 theta가 움직이는 방향이 맞는지? pi* D_i test 를 통해 optimize한 결과가 맞는지? MAML 요약 한게 맞는지? update는 batch 마다 이루어지는지 아니면 task마다 이루어지는 것이 맞는지? theta를 업데이트 할때 사용되는 loss함수는 벡터의 유사도를 비교함으로써 loss를 구하는건지? 
아래 그림에서 MAML has benefit of inductive bias without losing expressive power 하다는 것이 어떤 것을 의미하는지? assumstion 중 두번째 loss function gradient does not lose information about the label 은 무엇을 의미하는지? 
Add Point
- maml gradient 연산을 할때 full - hesse(헤시안) 행렬을 구하지 않고도 일부분을 구해 계산하는 기술이 존재한다
Optimization Meta-Learning
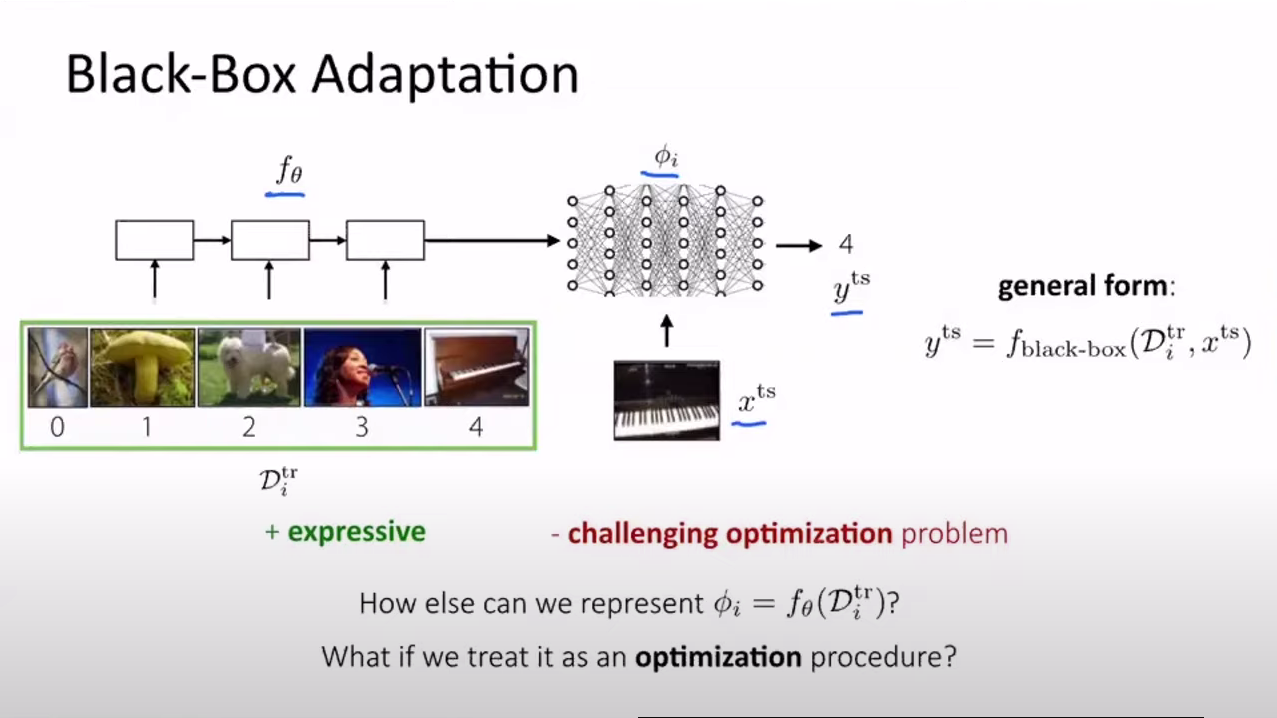
black-box adaptation에서 pi를 구하여 이를 통해 test와 함께 loss를 구하였다. 이번 강의에서는 optimization을 최적화하여 어떤 task에서도 빠르게 학습될 수 있는 파라미터를 찾으려고한다.
MAML
maml을 이해하기 위한 간단한 표식이다. 결론적으로 theta는 task1, task2, task3 전부에 대하여 가장 빨리 학습할 수 있는 theta값을 찾는 것이 목표이다. 아래 그림을 보면 theta 가 task에 의해 L1, L2, L3로 optimizing 된다 이 optimize 된 결과를 pi라고 할때 theta는 이 pi와 이후 update를 위해 test set 에서 optimize한 결과인 pi* 의 차이를 최소화하는 것을 목표로 삼는다. 결구 pi = pi* 가 되어야지만, 즉 모든 test task에 대해 최소한의 optimize를 통해 학습되는 theta를 찾는 방향으로 움직이게 되고
아래 그림의 빨간색 동그라미가 그 지점인 것이다. 현재 task마다 theta가 update 되는 것인지 그렇지 않고 한번에 task가 업데이트 되던 결국에는 test task 를 가장 빠르게 학습하는 방향으로 theta는 수렴할 것이다.
이에대해 나는 task 마다 train set이 test set을 통해 theta를 업데이트 하는 것을 도와주는데 지식을 전달한다고 생각한다. 즉 train set을 통해 fine-tuning을 하고 얻은 지식을 theta 를 update할때 사용하는 것이다. 이는 이후 다루겠지만 pretrained model과 다른 점 중 하나이다.

key idea는 결국 optimzation 을 통해 pi를 얻는 것이다.
black-box adaptation과 다르게 이 방식은 아래와 같은 방식으로 얻는다 이는 2차도함수를 활용하여 back - propagation을 진행한다.

결론적으로 black-box의 pi 는 그 자체로 새로운 task에 대한 정답길? 을 알려주지만 optimization adaptation은 새로운 task들을 학습하기 위한 최적의 길을 찾기 위해 이름과 같이 모델에 상관없이 적용가능하다는 점이다.
또한 maml은 compuatation graph로 볼 수 있다는 데 이는 나중 강의에서 더 복잡하게 다룬다고 한다.
ICLR 2018에 발표된 논문에 따르면 MAML function은 몇가지 assumtions 을 통해 거의 모든 funtion에 근사할 수 있다고 한다. 제약은 아래와 같다.
첫번쨰는 학습계수가 0이 아니라는 것 그리고 loss function gradient가 label의 정보를 잃지 않아야한 다는 것인데 … 무슨소린지 잘 이해가 안감
그리고 세번째는 datapoints in D_tr_i가 유일해야한다는 것이다.
MAML has benefit of inductive bias without losing expressive power. 하다는 점에서 중요하다고한다. - 질문 필요

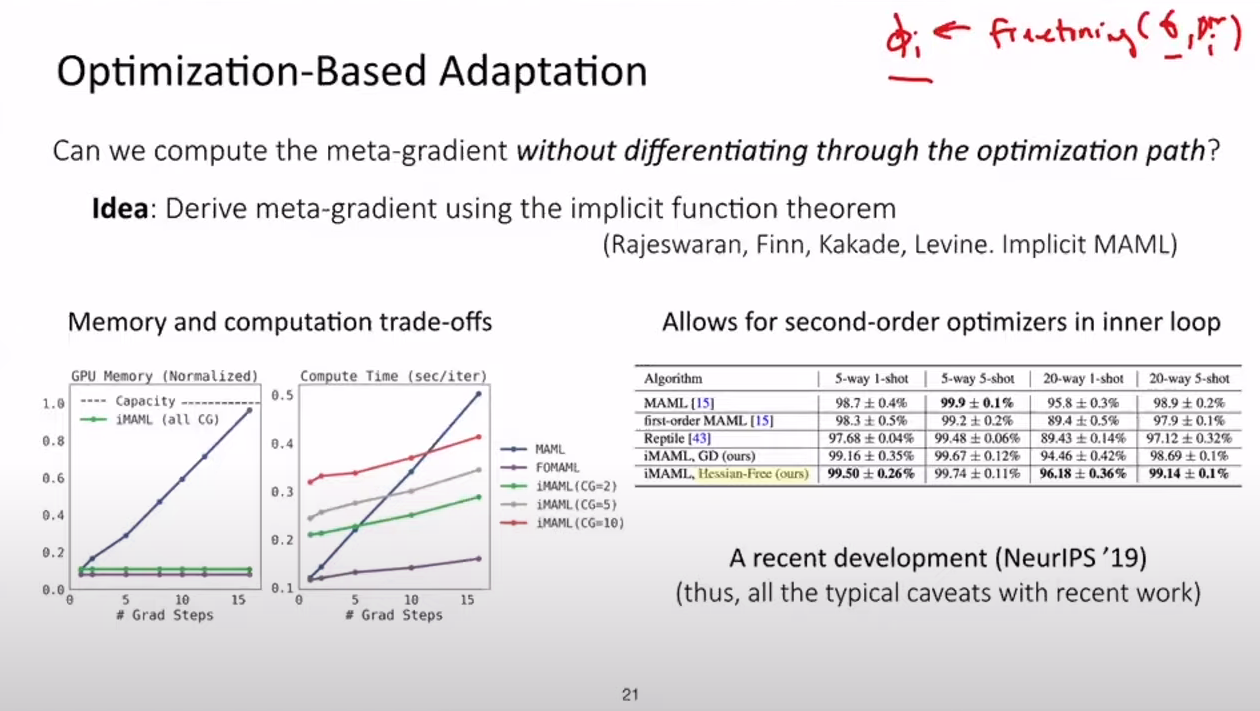
다음은 Optimization-Based Adaptation 가 가지는 문제들과 그 해결책에 대해 말한다.
첫번째는 gradient descent 안에 gradient descent가 들어가 있는 이중 구조가 학습이 불안정하다는 문제이다. 이를 해결하기 위해 몇가지 아이디어가 있는데 하나는 inner vector의 learning rate를 자동적으로 학습시키는 것이다. 실제로 교수는 inner learning rate가 학습에 매우 중요한 요소라고 말한다.
또다른 아이디어는 내부 루프에서 하위 집합의 파라미터만을 optimize하는 것이다. 이렇게 함으로써 불안성을 줄인다. - 한번에 많은 학습을 하지 않겠다? 라는 의미인것 같다. 마지막으로 문맥 변수를 추가하여 학습진행속도를 늦출 수 있다고한다. 바닐라 모델도 충분한 성능을 보이지만 이러한 간단한 트릭이 도움이된다고한다.

다음 문제는 계산량의 문제이다. 이를 해결하기위한 첫번째 아이디어는 d_pi / d_theta 르 ㄹidentity vector로 근사시킨다는 것인데, 정확한 원리는 생략한다. 놀랍게도 few-show prblem에서는 잘 작동하지만 어려운 문제를 해결하는데는 문제가 있다고한다.
두번째 아이디어는 last layer만 업데이트를 하는 것이다 마지막으로는 implict function theorem을 사용하여 meta=gradient를 유도한다는 것이다 이 또한 상세한 내용은 강의에서 생략한다.

maml이 좋은 성능을 보이는 것은 sub task 과 main task의 이중 optimizer 형태가 가능하기 때문이라고 한다. 왜냐하면 maml에서는 끝까지 업데이트를 하지 않으므로 back-propagation 을 2차로 할 필요가 없고 이는 메모리적으로 작은 연산 메모리를 필요로한다는 것이다.
세번째 문제는 내부의 gradient step에서 어떤 구조가 효과적인지 찾아야 한다는 것이다. 이전의 실험을 통해 큰 신경망에 더불어 비정형화된 신경망이 성능이 뛰어났다고한다.

maml을 사용하는 것이 이점이 되는 것이 bi-level optimization problem 을 구성한 점이라고 한다. 따라서 메타 학습을 시작할때 긍정적 귀납적 bias를 얻게 된다고 한다 - 아마 pretrained 된 모델에서 추출한 bias 라고 생각이 된다./ 또한 optimization 구조를 통해 학습률 혹은 최적화를 개선할 수 있다고 한다.
그리고 네트워크가 충분히 큰 경우에도 표현력이 커저 도움이된다.