[CS330] lecture5 review
in Summary on Summary, Cs330
QnA
Preview
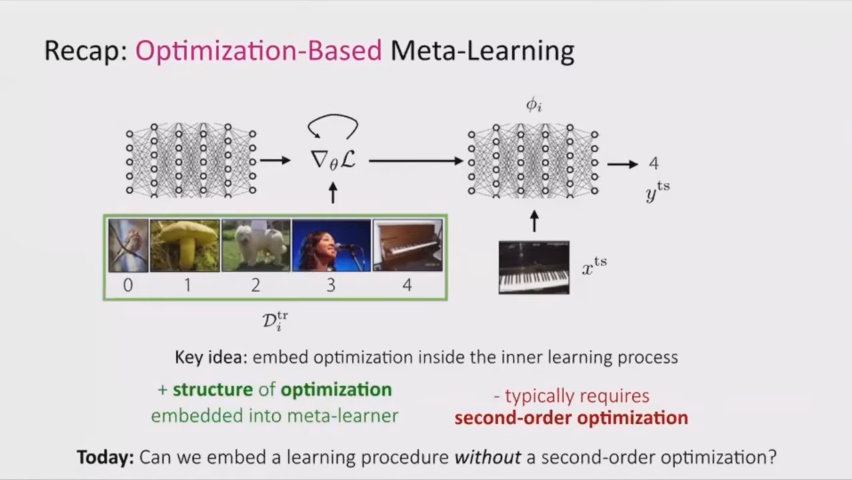
이전에 보았던 optimization- based meta learning은 optimize를 2번 계산하면서 meta learner를 embed하였고 이는 좋은 성능을 가져왔다 하지만 연산량또한 올라가 gpu및 메모리가 부족하게 되고 또한 학습또한 불안정하게 진행된다.
이를 해결하기 위해 second-order optimization 없이 learning procedure을 embed하는 방법을 소개한다.

Non-parametric하다는 것은 저차원 공간에서 단순하고 사실 동작도 잘한다. 이렇게 생각할 수 있다. meta-test time동안에는 few-shot learning을 진행할 것이고 이는 매우 간단한 data의 집합을 가질 것이다 반면에 meta-training 과정에서는 복잡한 연산을 해야하므로 여전히 parametric해야한다.
즉 핵심은 파라미터로 학습한 meta-learner가 non-parametic한 부분에서도 잘 동작하느가를 묻고 있다

non -parametric method 는 test datapoint 와 training data set을 비교하여 그 차이(loss)를 계산한다.

이는 다음과같이 샴네트워크를 통해 두 이미지가 같을 경우 1을 다른 이미지라 판단하면 0을 label로 출력한다. 이러한 과정을 하나의 x_test 이미지씩 각각의 모든 train_data를 비교한다
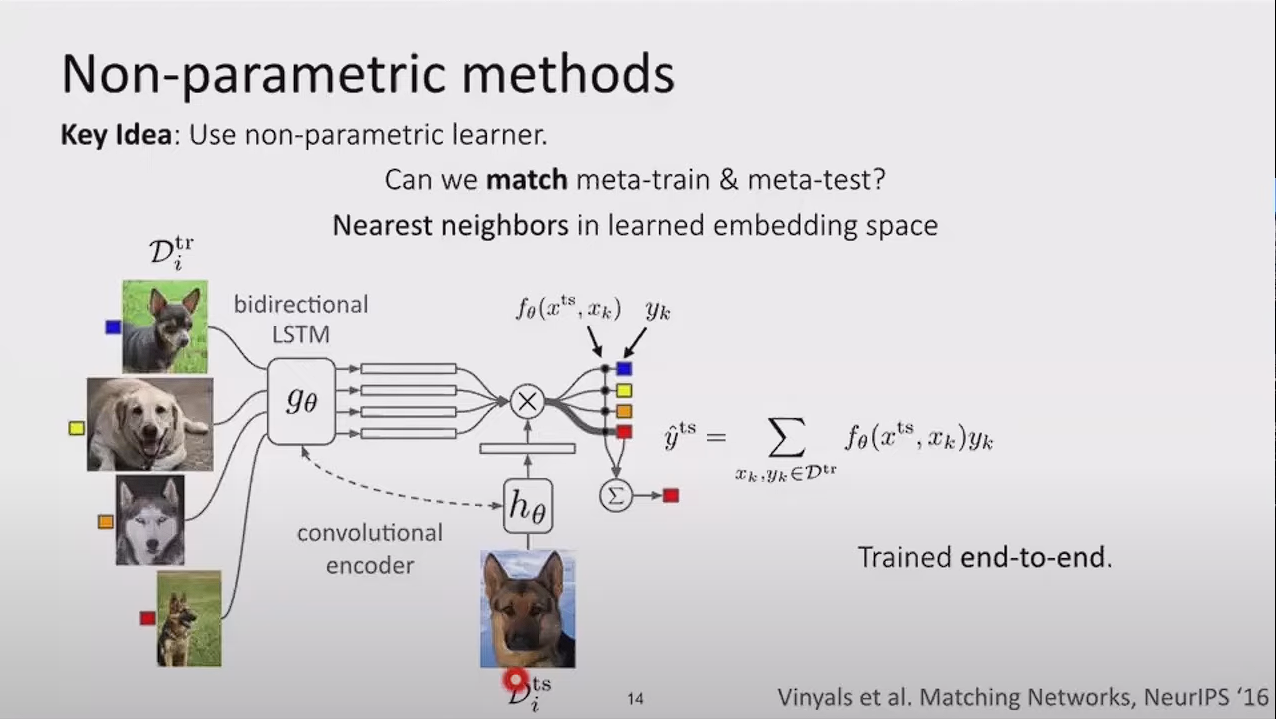
학습과정은 다음과 같이 바뀐다. sampling까지 동일하고, 이후 meta-learning with non-parametic을 위해 train data와 test data간의 비교를 통해 학습을 한다. 그리고 이를 매칭 네트워크라고 한다. 이는 few-shot learning의 대표적인 방식입니다.
여기서 강사는 만약 하나이상의 에시가 있다면 어떻게 할것인가? 라는 질문을 하였다. 이는 위에서 보았던 4종류의 강아지를 비교할떄 만약 한종류의 개가 2마리 있을경우 다른 한마리에 대해서도 임베딩 벡터가 생겨날 것이고 한 레이블에 두개의 임베딩 벡터가 생길 것이다.물론 큰 문제는 없을 것 같지만 연산량에서 문제가 생길 수 도 있을 것이다.

또한 같은 레이블에 임베딩된 벡터가 많을 경우 이를 평균화 해서 centroids를 구한다. 이후 input x는 이 centroid를 기반으로 가까운 곳, 즉 유사도를 측정하여 predict을 구할 수있다.
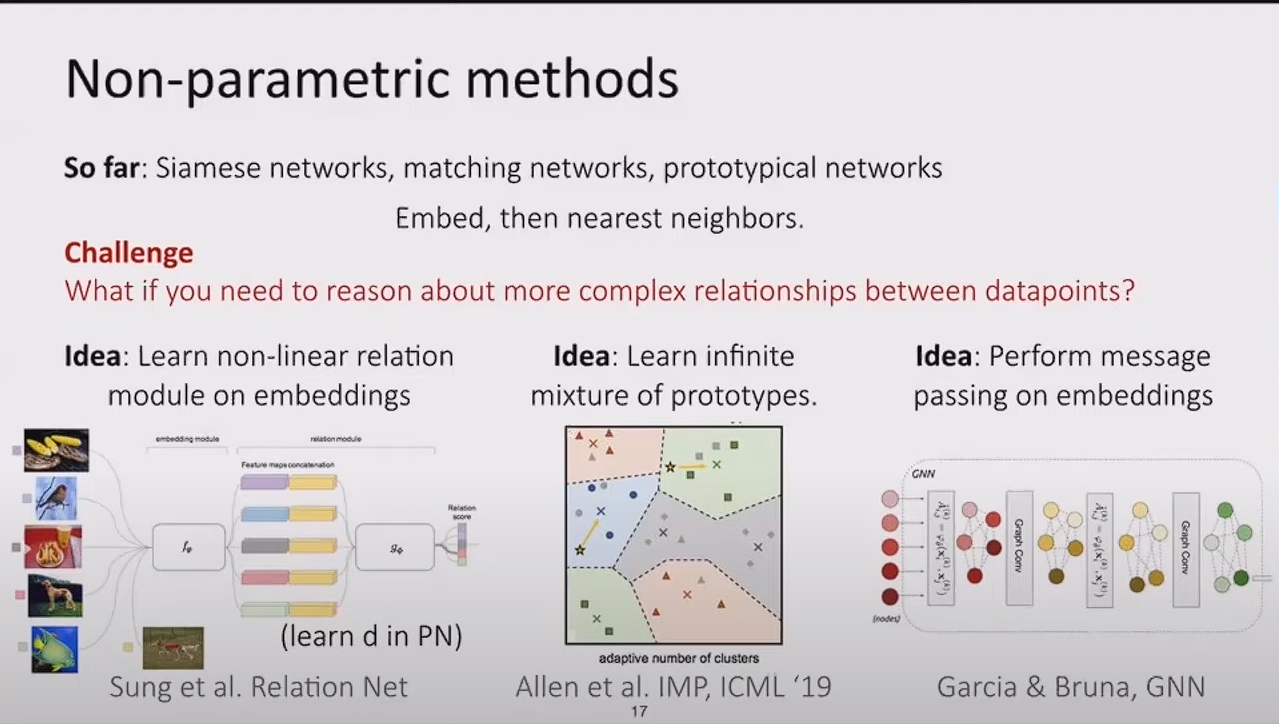
그렇다면 데이터들 사이에서 단순한 네트워크 만으로는 구별이 되지않을 수 도 있다 - 데이터의 형태가 복잡하다면, 이때 사용할 수 있는 방법은 3가지인데 이를 섞에서 사용하던가 변형해서 사용함으로써 성능을 올릴 수 있다고 한다.
첫번째는 비선형함수를 네트워크에 추가하여 그 복잡성을 늘리는 것이다. 두번째는 클래스에 대해 너무 많은 특징이 존재한다면 ex) 사람과 동물 비교- 사람과 동물은 가지각색이라서 많은 특징을 필요로한다. 따라서 생겨난 다양한 특징을 mix할 수 있는 네트워크를 생성하여 좀더 단순화? 하는 것이 목표인듯 하다.
마지막으로는 각각의 클래스에 대해 복잡한 관계가 형성되었을 경우 GNN을 통해 해결할 수 도 있다고한다.
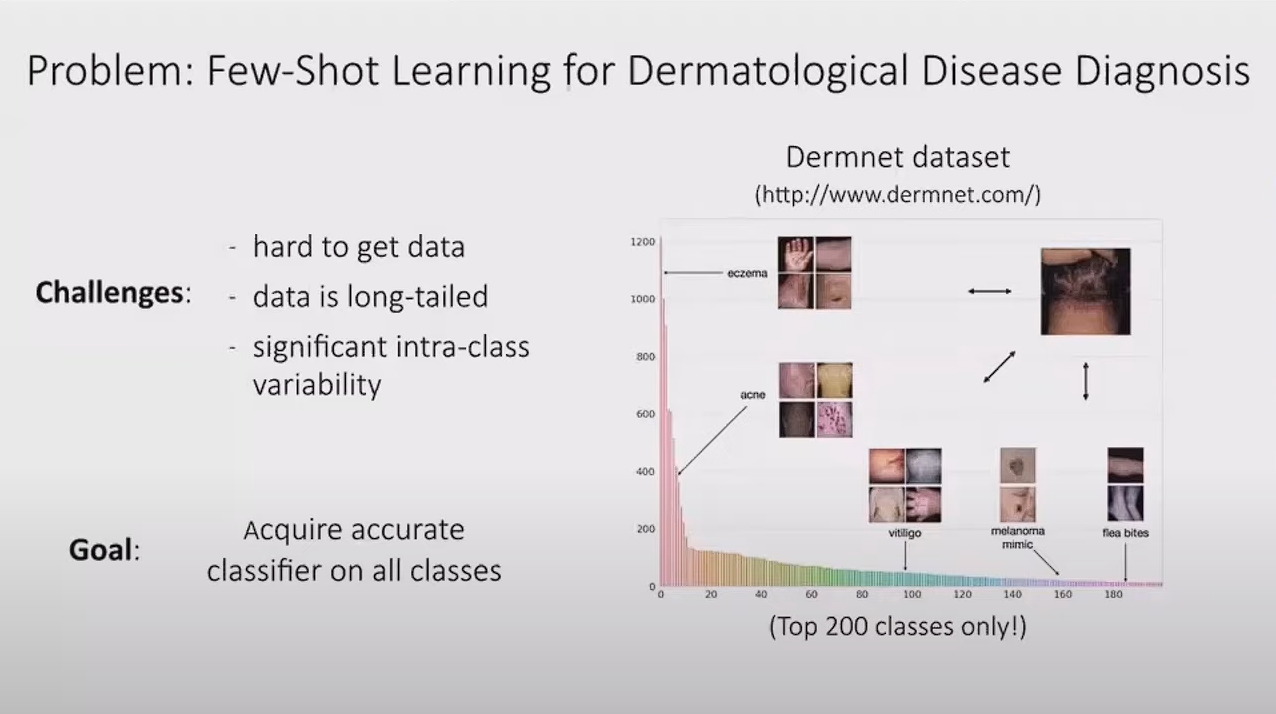
실제 예시를 가져온다면 피부 질환 진단에 대한 내용이다. 이는 meta learing이 적용되기 좋은 사례라고 할 수 있다. 클래스는 많은데 example이 없는 경우로 정확하게 분류하는것이 이 문제의 목적이다.

이 믄제에서 접근하기 위해 prototupical clustering networks 를 수행해야한다. 이를 위해 아까 보았던 알고리즘을 활용할 수 있다.
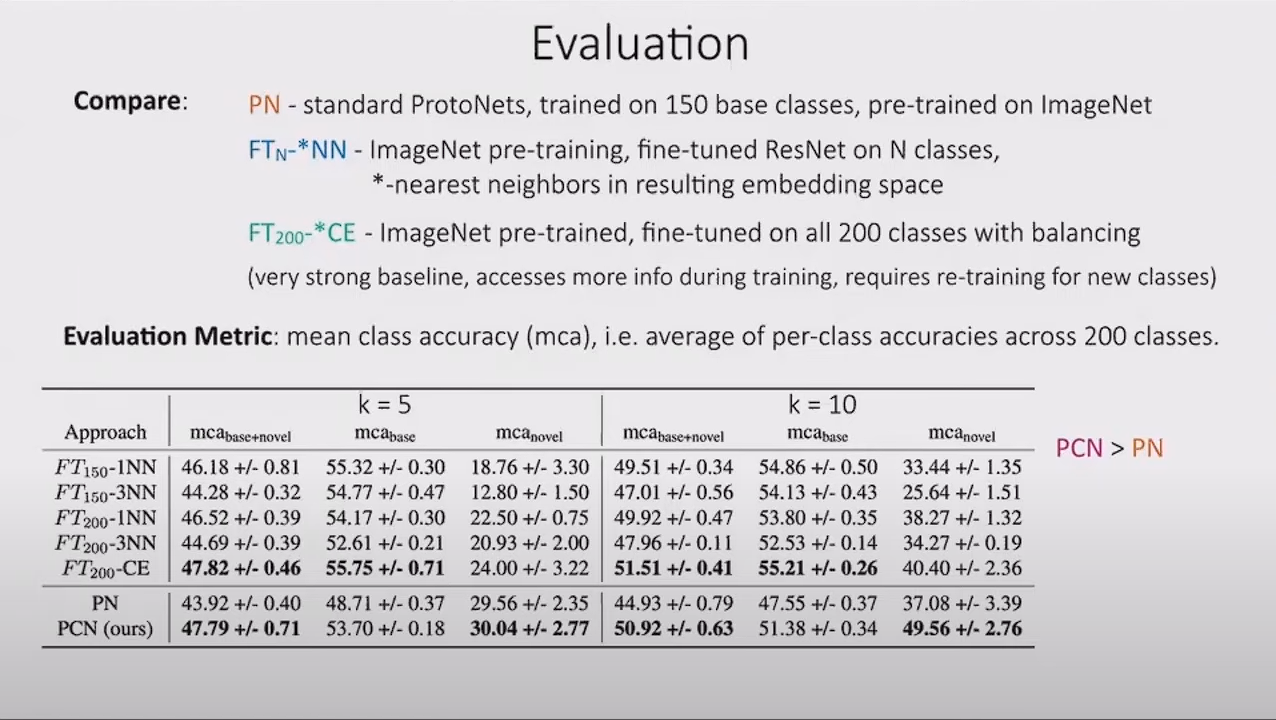
성능 평가를 보면 prototypical clustering netowrk가 기본 pretrained된 모델 뿐 아니라 fine-tuning된 모델 보다도 성능이 우수하게 나온다는 것을 확인 가능하다. 이후 내용에서는 텍스트 분류문제에서도 훌룡하게 작동할 것이라고 말하였다.

메타 러닝의 성능을 객관화 하기 위해 요소를 소개 하였는데 expressive power즉 얼마나 넣ㅂ은 도메인에서 적용한가, 그리고 consistency의 경우 데이터가 증가할수록 성능이 증가하여 메타러닝적 요소를 완화하는 것이 그 기준이다.

위에 보이는 것처럼 3가지의 메소드는 case마다 성능이 더 좋을 수도 있고 않좋을 수도 있다. 이는 잘 tuning된 모델에 한해서이다. 마지막으로 배 웠던 non-parametric한 방법도 class가 너무 많거나 다양하게 존재할 경우 일반화 하기 힘들고 분류문제에 한계가 존재한다.

마지막으로 학습과정을 이해할 수 있는가에 대한 논의 인데 이는 tuning을 할때 필요한 접근이기 때문이다.
metalearning applliation

첫번째의 경우 사람의 영상을 메타러닝하여 일반적인 동작을 학습하고, 이는 MAML로 학습된다, 이후 시연영상이 test data로 주어지면 똑같이 이를 수행한다.

다음은 few-shot human motion prediction이다 단순하게 user의 motion을 training data로 주고 이후 test dataset에서 다음에 들어올 혹은 중간에 빈 동작을 예측하는 문제이다. 이는 optimization-based/black-box hybrid의 형태로 해결하였다고 한다.
